
O ChatGPT ainda reina supremo em muitos rankings de IA, mas a competição está em alta
Qual é o modelo de inteligência artificial mais poderoso em determinado momento? Confira as tabelas de classificação.
Rankings construídos pela comunidade de modelos de IA publicados publicamente on-line aumentaram em popularidade nos últimos meses, oferecendo uma visão em tempo real da batalha em curso entre as principais empresas de tecnologia pela supremacia da IA.
Cada tabela de classificação rastreia quais modelos de IA são os mais avançados com base em sua capacidade de concluir determinadas tarefas. Um modelo de IA em sua raiz é o conjunto de equações matemáticas envoltas em código projetado para atingir um objetivo específico.
Alguns novos participantes, como o Gemini do Google (ex-Bard) e o Mistral-Medium, da startup Mistral AI, com sede em Paris, despertaram entusiasmo na comunidade de IA e disputaram vagas perto do topo do ranking.
O GPT-4 da OpenAI, no entanto, continua a dominar.
“As pessoas se preocupam com o estado da arte”, disse Ying Sheng, cocriador de uma dessas placares, a Chatbot Arena, e doutorando em ciência da computação na Universidade Stanford. “Acho que as pessoas realmente gostariam mais de ver que as tabelas de classificação estão mudando. Isso significa que o jogo ainda está lá e ainda há mais melhorias a serem feitas.”
Os rankings são baseados em testes que determinam do que os modelos de IA são geralmente capazes, bem como qual modelo pode ser mais competente para um uso específico, como reconhecimento de fala. Os testes, também chamados de benchmarks, medem o desempenho da IA em métricas como como o áudio da IA humana soa ou como a resposta humana de um chatbot de IA aparece.
A evolução desses testes também é importante à medida que a IA continua avançando.
“Os benchmarks não são perfeitos, mas, a partir de agora, essa é a única maneira que temos de avaliar o sistema”, disse Vanessa Parli, diretora de pesquisa do Instituto de Inteligência Artificial Centrada no Ser Humano de Stanford.
O instituto produz o Índice de IA de Stanford, um relatório anual que rastreia o desempenho técnico de modelos de IA em várias métricas ao longo do tempo. O relatório do ano passado analisou 50 benchmarks, mas incluiu apenas 20, disse Parli, e o deste ano vai novamente raspar alguns benchmarks mais antigos para destacar os mais novos e abrangentes.
As tabelas de classificação também oferecem um vislumbre de quantos modelos estão em desenvolvimento. O Open LLM (modelo de linguagem grande) Leaderboard construído pela Hugging Face, uma plataforma de aprendizado de máquina de código aberto, havia avaliado e classificado mais de 4.200 modelos até o início de fevereiro, todos enviados por membros de sua comunidade.
Os modelos são rastreados em sete benchmarks principais que visam avaliar uma variedade de capacidades, como compreensão de leitura e resolução de problemas matemáticos. As avaliações incluem testar os modelos em questões de matemática e ciências do ensino fundamental, testar seu raciocínio de senso comum e medir sua propensão a repetir desinformação. Alguns testes oferecem respostas de múltipla escolha, enquanto outros pedem que os modelos gerem suas próprias respostas com base em prompts.
Os visitantes podem ver como cada modelo se comporta em benchmarks específicos, bem como qual é sua pontuação média geral. Nenhum modelo ainda alcançou uma pontuação perfeita de 100 pontos em qualquer benchmark. O Smaug-72B, um novo modelo de IA criado pela startup Abacus.AI, com sede em São Francisco, recentemente se tornou o primeiro a ultrapassar uma pontuação média de 80.
Muitos dos LLMs já estão superando o nível de desempenho da linha de base humana em tais testes, indicando o que os pesquisadores chamam de “saturação”. Thomas Wolf, cofundador e diretor científico da Hugging Face, disse que isso geralmente acontece quando os modelos melhoram suas capacidades a ponto de superarem testes de referência específicos – muito parecido com quando um aluno muda do ensino fundamental para o ensino médio – ou quando os modelos memorizam como responder a certas perguntas do teste, um conceito chamado “overfitting”.
Quando isso acontece, os modelos se saem bem em tarefas executadas anteriormente, mas lutam em novas situações ou em variações da tarefa antiga.
“A saturação não significa que estamos ficando ‘melhores do que os humanos’ em geral”, escreveu Wolf em um e-mail. “Isso significa que, em benchmarks específicos, os modelos chegaram a um ponto em que os benchmarks atuais não estão avaliando suas capacidades corretamente, então precisamos projetar novos.”
Alguns benchmarks existem há anos, e torna-se fácil para os desenvolvedores de novos LLMs treinar seus modelos nesses conjuntos de teste para garantir pontuações altas após o lançamento. O Chatbot Arena, um grupo de pesquisa aberto intercolegial chamado Large Model Systems Organization, visa combater isso usando a entrada humana para avaliar modelos de IA.
Parli disse que essa também é uma maneira que os pesquisadores esperam obter para serem criativos na forma como testam modelos de linguagem: julgando-os de forma mais holística, em vez de olhar para uma métrica de cada vez.
“Especialmente porque estamos vendo benchmarks mais tradicionais ficarem saturados, trazer a avaliação humana nos permite chegar a certos aspectos que os computadores e mais avaliações baseadas em código não conseguem”, disse ela.
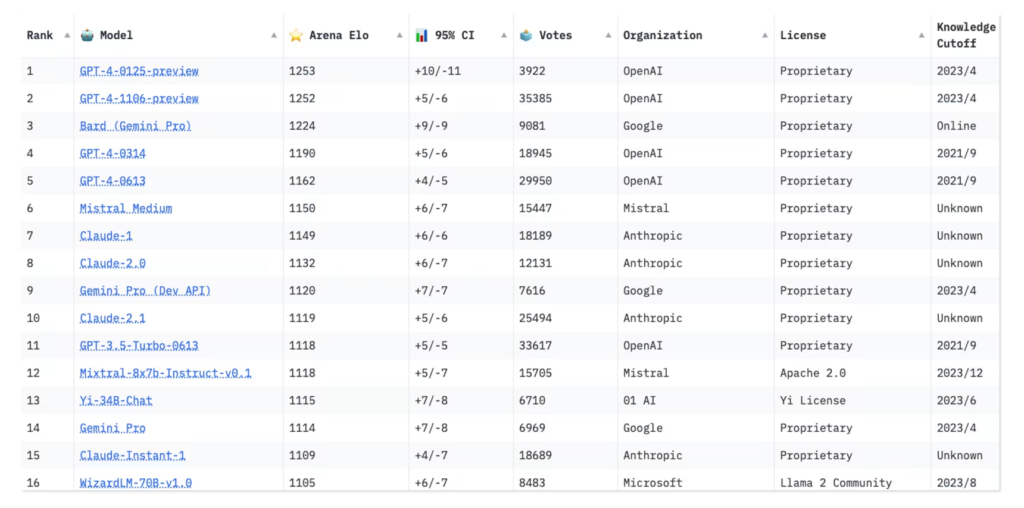
O Chatbot Arena permite que os visitantes façam qualquer pergunta que quiserem a dois modelos de IA anônimos e, em seguida, votem em qual chatbot dá a melhor resposta.
Sua tabela de classificação classifica cerca de 60 modelos com base em mais de 300.000 votos humanos até agora. O tráfego para o site aumentou tanto desde o lançamento do ranking, há menos de um ano, que a Arena agora está recebendo milhares de votos por dia, de acordo com seus criadores, e a plataforma está recebendo tantos pedidos para adicionar novos modelos que não consegue acomodar todos eles.
O cocriador do Chatbot Arena, Wei-Lin Chiang, estudante de doutorado em ciência da computação na Universidade da Califórnia-Berkeley, disse que a equipe conduziu estudos que mostraram que os votos por crowdsourcing produziram resultados quase tão de alta qualidade quanto se tivessem contratado especialistas humanos para testar os chatbots. Inevitavelmente haverá outliers, disse ele, mas a equipe está trabalhando na criação de algoritmos para detectar comportamentos maliciosos de eleitores anônimos.
Por mais úteis que sejam os benchmarks, os pesquisadores também reconhecem que eles não são abrangentes. Mesmo que um modelo tenha bons resultados em benchmarks de raciocínio, ele ainda pode ter um desempenho inferior quando se trata de casos de uso específicos, como a análise de documentos legais, escreveu Wolf, cofundador da Hugging Face.
É por isso que alguns entusiastas gostam de realizar “verificações de vibe” em modelos de IA, observando como eles se comportam em diferentes contextos, acrescentou ele, avaliando assim como esses modelos conseguem se envolver com os usuários, reter boa memória e manter personalidades consistentes.
Apesar das imperfeições do benchmarking, os pesquisadores dizem que os testes e as tabelas de classificação ainda incentivam a inovação entre os desenvolvedores de IA, que devem constantemente elevar o nível para acompanhar as últimas avaliações.
Por Angela Yang
Fonte: ABC News

